
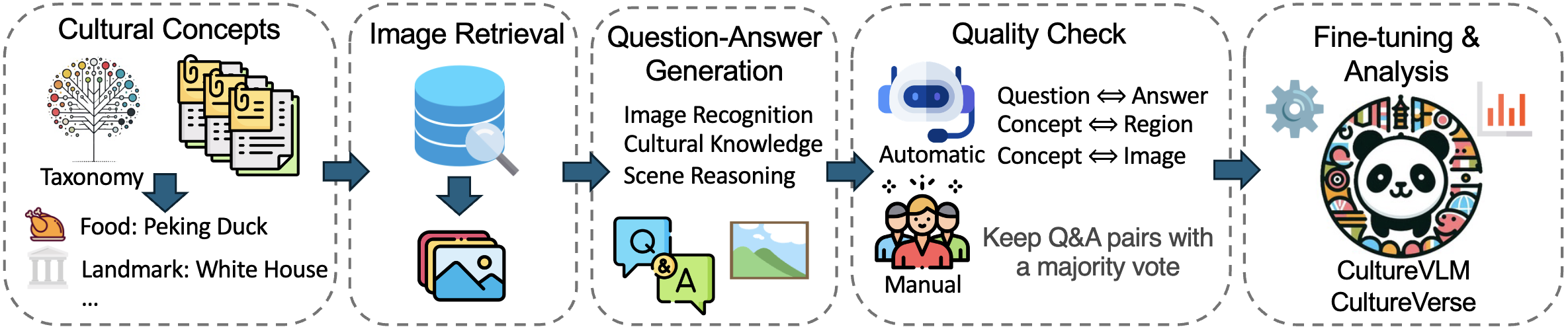
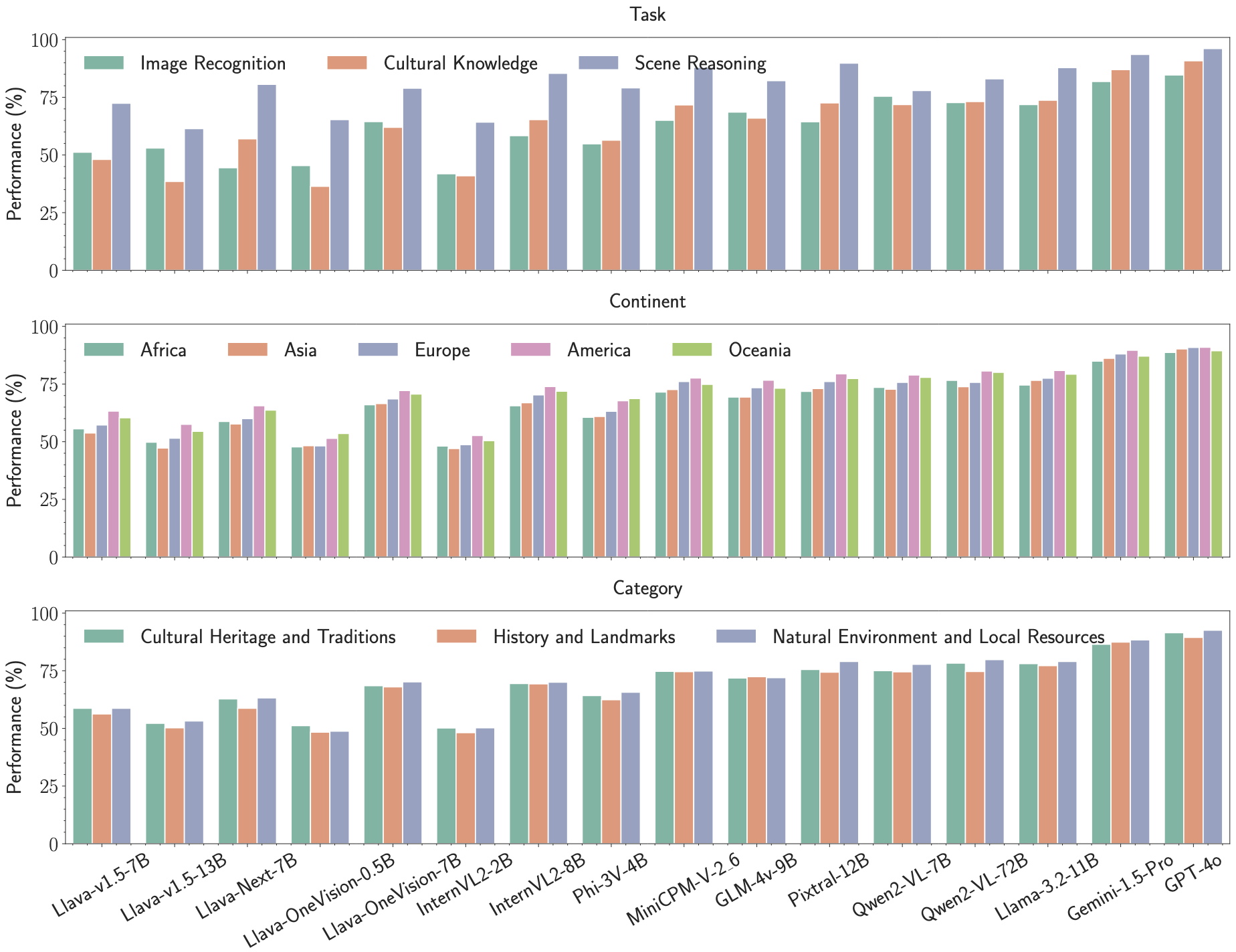
Vision-language models (VLMs) have advanced human-AI interaction but struggle with cultural understanding, often misinterpreting symbols, gestures, and artifacts due to biases in predominantly Western-centric training data. In this paper, we construct CultureVerse, a large-scale multimodal benchmark covering 19, 682 cultural concepts, 188countries/regions, 15 cultural concepts, and 3 question types, with the aim of characterizing and improving VLMs’ multicultural understanding capabilities. Then, we propose CultureVLM, a series of VLMs fine-tuned on our dataset to achieve significant performance improvement in cultural understanding. Our evaluation of 16 models reveals significant disparities, with a stronger performance in Western concepts and weaker results in African and Asian contexts. Fine-tuning on our CultureVerse enhances cultural perception, demonstrating cross-cultural, cross-continent, and cross-dataset generalization without sacrificing performance on models’ general VLM benchmarks. We further present insights on cultural generalization and forgetting. We hope that this work could lay the foundation for more equitable and culturally aware multimodal AI systems.
@article{liu2025culturevlm,
title={CultureVLM: Characterizing and Improving Cultural Understanding of Vision-Language Models for over 100 Countries},
author={Liu, Shudong and Jin, Yiqiao and Li, Cheng and Wong, Derek F and Wen, Qingsong and Sun, Lichao and Chen, Haipeng and Xie, Xing and Wang, Jindong},
journal={arXiv preprint arXiv:2501.01282},
year={2025}
}